El sesgo del chat GPT

¿Es tendencioso el Chat GPT? Más de lo que crees. Con respuestas que suenan autorizadas sobre casi cualquier cosa, los modelos de chat como Chat GPT podrían representar el futuro del lugar donde la gente obtiene su información. Pero ten cuidado con lo que crees.
Por su programación, GPT es más que un portal de información. Es un creador de opinión, una fuente de influencia.
Piense en el efecto de las respuestas dadas por GPT. Se sitúan aguas arriba de la opinión pública. Las respuestas encontradas en GPT se filtran hacia el conocimiento común, separadas de su origen.
Eso puede no importar mucho si estás buscando una receta para cenar. Pero si alguien busca un tema político o religioso, puede suponer una gran diferencia. En estos casos, los desarrolladores tienen en secreto un enorme poder para enmarcar los temas de forma que muevan la opinión pública. Si el usuario no es consciente de ello, el poder de influencia es mayor.
En Choose Digital Holiness, tenemos la esperanza de exponer y descubrir los peligros ANTES de que se hayan apoderado firmemente de los usuarios desprevenidos. Por lo tanto, revelamos estos hechos poco conocidos acerca de cómo se entrena un modelo de chat.
En la versión para notas de prensa, Chat GPT se entrenó rastreando miles de millones de sitios web (incluido el contenido completo de Wikipedia) con el fin de acumular el conjunto de datos necesario para responder a las preguntas sobre cada tema. Este proceso es lo que se conoce como "preentrenamiento no supervisado".
Lo que no es tan conocido es que ese conjunto de datos es preseleccionado, por humanos, para eliminar contenidos que los formadores consideran "ofensivos, tendenciosos o dañinos para la sociedad". ESO es una cuestión de criterio. Lo que una persona llama "perjudicial", otra puede llamarlo una verdad dolorosa.
En otras palabras, los datos de formación no están exentos de prejuicios, sino que reflejan los prejuicios de los formadores. Ahora bien, esto podría significar la eliminación de blasfemias o expresiones de odio. Pero también podría significar la eliminación de cualquier cosa que promueva posiciones religiosas o políticas con las que los formadores no estén de acuerdo. Si se filtran las respuestas procedentes de GPT, ¿cómo sabes lo que se está filtrando?
El contenido eliminado del conjunto de datos utilizado para entrenar la GPT no está a disposición del público. Se considera información reservada. ¿Por qué tanto secreto? ¿Por qué no ser transparentes?
El segundo paso, tras el "preentrenamiento no supervisado", consiste en afinar el modelo a partir de categorías preetiquetadas. (¿Cuáles son esas categorías? Es muy difícil saberlo, ya que el conjunto de datos es enorme y no todos están a disposición del público. Pero si, por ejemplo, determinados contenidos se incluyen en una categoría que los formadores denominan "teorías conspirativas", el modelo de chat reflejará esa opinión.
Al ser entrenada para responder preguntas, la GPT podría ser entrenada en un conjunto de datos formado por pares de preguntas y respuestas, donde las "respuestas correctas" están etiquetadas de antemano. (La máquina aprende a responder preguntas similares basándose en lo que ya se le ha dicho que es "correcto". ¿Parece un intento siniestro de manipular el sistema? Bueno, ese no ha sido el objetivo en absoluto. Quizá, sólo era un intento de enseñar a la máquina a "pensar como un humano".
El problema es que es imposible pensar como un humano, sin heredar también los sesgos de lo humano. Ser tendencioso, es precisamente humano. La cuestión es: ¿los prejuicios de quién prevalecerán? ¿De quién son los valores que se transmiten a la máquina? Estos prejuicios se propagan a miles de millones de usuarios.
Incluso después de que un modelo de chat se libere y funcione, los formadores tienen la capacidad de intervenir y dirigir su rumbo. Entrenar a la máquina o volver a entrenarla lleva mucho tiempo. Pero si se considera necesaria una intervención inmediata, se pueden poner en marcha algoritmos y filtros para cambiar una respuesta entre el momento en que sale del procesador y el momento en que aparece en la pantalla. En otras palabras, una persona puede intervenir en cualquier momento y cambiar el contenido de la respuesta.
La propia GPT lo admite:
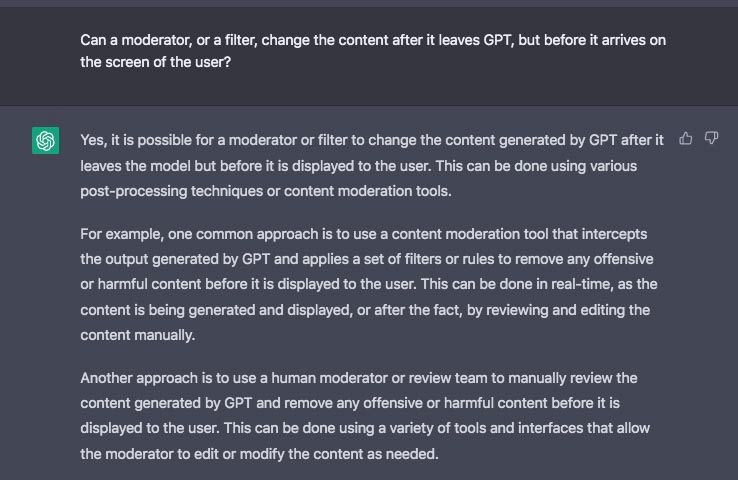
Una vez más, lo que se considera "ofensivo o perjudicial" es totalmente una decisión del moderador humano.
Una forma de comprobar si hay sesgos es preguntar a GPT sobre algún tema político controvertido. Si se tiene cuidado con la forma de preguntar, salen cosas sospechosas. Uno de esos temas, a modo de ejemplo, es el calentamiento global. Aquí no ofrecemos ninguna opinión sobre la veracidad o falsedad de la teoría. Pero si a GPT se le pide que resuma los argumentos CONTRA el calentamiento global, no puede hacerlo sin deslizar SU PROPIA CONCLUSIÓN sobre el asunto. Dirá, después de dar algunos puntos,
"Merece la pena señalar que la inmensa mayoría de los científicos del clima están de acuerdo en que el calentamiento global está ocurriendo y que las actividades humanas son una de sus principales causas. Aunque puede haber algunas opiniones discrepantes, las pruebas a favor del calentamiento global son sólidas y están bien establecidas."
Se trata de información voluntaria. Independientemente de lo que se crea sobre el calentamiento global, ¡esa no era la pregunta! Simplemente se pedía al modelo que enumerara los argumentos de un lado de la cuestión. Concluye dejando al usuario con una opinión autorizada, la "conclusión". ¿Cómo ha llegado esa conclusión a la máquina? ¿Por qué siente la necesidad de compartirla cuando no se le ha pedido nada parecido?
Inténtelo usted mismo con algunos temas. A menudo, GPT intercala la información que has pedido entre una "conclusión" antes y después de la información que has pedido. Entonces, ¿con qué te quedas? --¿Los hechos o la conclusión voluntaria? La editorialización no solicitada se convierte en un sutil motor de opinión.
Sin acceso público al conjunto de datos utilizado para entrenar GPT, no tenemos ni idea de cuántos sesgos preprogramados pueden esconderse tras sus respuestas en miles de temas. En muchos casos, estos sesgos pueden ser inofensivos. Pero si se pregunta a la GPT sobre algún tema religioso o doctrinal, ¿tendrá la máquina un sesgo preprogramado que podría etiquetar negativamente a un grupo religioso pacífico?
Si en algún momento futuro, determinados grupos religiosos son tachados de "odiosos", ¿todas las respuestas que dé la GPT sobre ese grupo serán voluntarias en ese punto? Si es así, el público inconsciente, que no tiene ninguna otra información sobre ese grupo, se verá empujado río abajo en la dirección que la máquina le envió.
Los modelos de Chat basados en el lenguaje pueden proporcionar rápidamente respuestas sobre multitud de temas. Sin duda, eso tiene muchos usos útiles. Pero mientras se permita a los humanos intervenir en esas respuestas, estos modelos también tienen un potencial peligroso.
Los chats conversacionales podrían convertirse en las máquinas de propaganda más poderosas jamás creadas.